Deploying a transformer
A transformer can be used to:
- Enhance your input data with data from a database/feature store
- Add preprocessing and feature engineering prior to creating predictions and explanations
- Add postprocessing to your predictions or explanations
- Retrieve data for job schedules
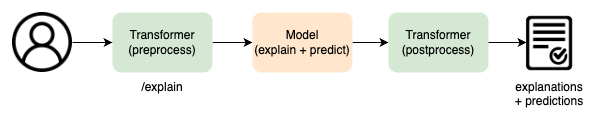
Transformers come in the form of custom docker containers. Templating functionality is available in the Deeploy python client CLI to make implementing a transformer for the above use cases easy. Transformers modify the "normal" request flow. A transformer always serves as both the entrypoint and exit point. Below is an overview of how data flows through the different deployment artifacts.
Model and transformer

Model, trained explainer and transformer

For PDP tabular and MACE tabular explainers, the preprocessing and postprocessing needs to be replicated in the explainer object. The transformer will be skipped here when making explanations. See explain.py as example.
Model, standard/integrated explainer and transformer
Job schedules predict
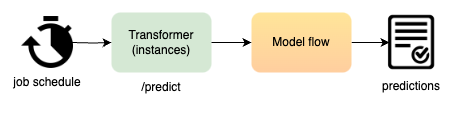
Model flow is similar to the flow in the first diagram.
Job schedules explain
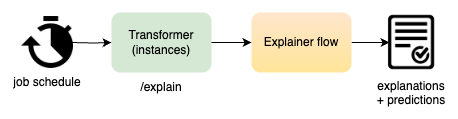
Explainer flow is either the second or third diagram based on your configuration.